

Introduction
The release of Code Llama, a powerful large language model (LLM) focused on coding tasks, represents a major breakthrough in the field of generative AI for coding.


Code Llama is designed to generate code, explain code segments, and assist with debugging based on natural language prompts.
This model has achieved impressive results, outperforming existing code-specific language models and showcasing the potential of task-specific models to surpass larger, more general-purpose models.
This development is significant as it demonstrates the narrowing gap between proprietary models and open-source models, particularly in specific applications like coding. The release of Code Llama has the potential to revolutionize code development workflows and education in the field of programming.
Code Llama: A Breakthrough in Coding Language Models
Code Llama is introduced as a state-of-the-art LLM that excels in generating code and providing explanations and debugging assistance.
It is trained on both code and natural language prompts, allowing it to generate code in response to natural language instructions and explain existing code segments. This versatility makes Code Llama a valuable tool for both experienced programmers and those learning to code.
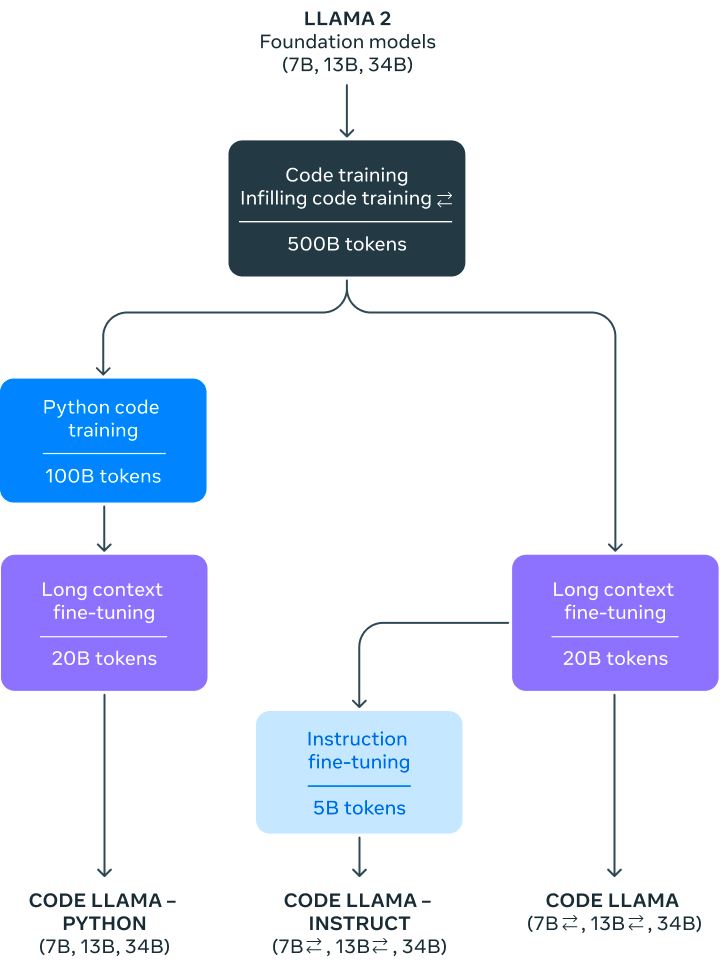
The three models released under the Code Llama umbrella are Code Llama (the foundational code model), Code Llama - Python (specialized for Python), and Code Llama - Instruct (fine-tuned for understanding natural language instructions).
Each model is available in different sizes, with the 34 billion parameter model being the most capable but also having higher latency. The smaller 7 billion and 13 billion parameter models offer faster performance but still deliver impressive results.
Training and Performance of Code Llama
Code Llama is built on top of the Llama 2 model, which has undergone extensive training and fine-tuning to enhance its coding capabilities. The model was trained on a large dataset of code-related tokens, with variations specific to Python and natural language instructions.
The training process involved billions of tokens, resulting in models that can handle up to 100,000 tokens of context in code generation.
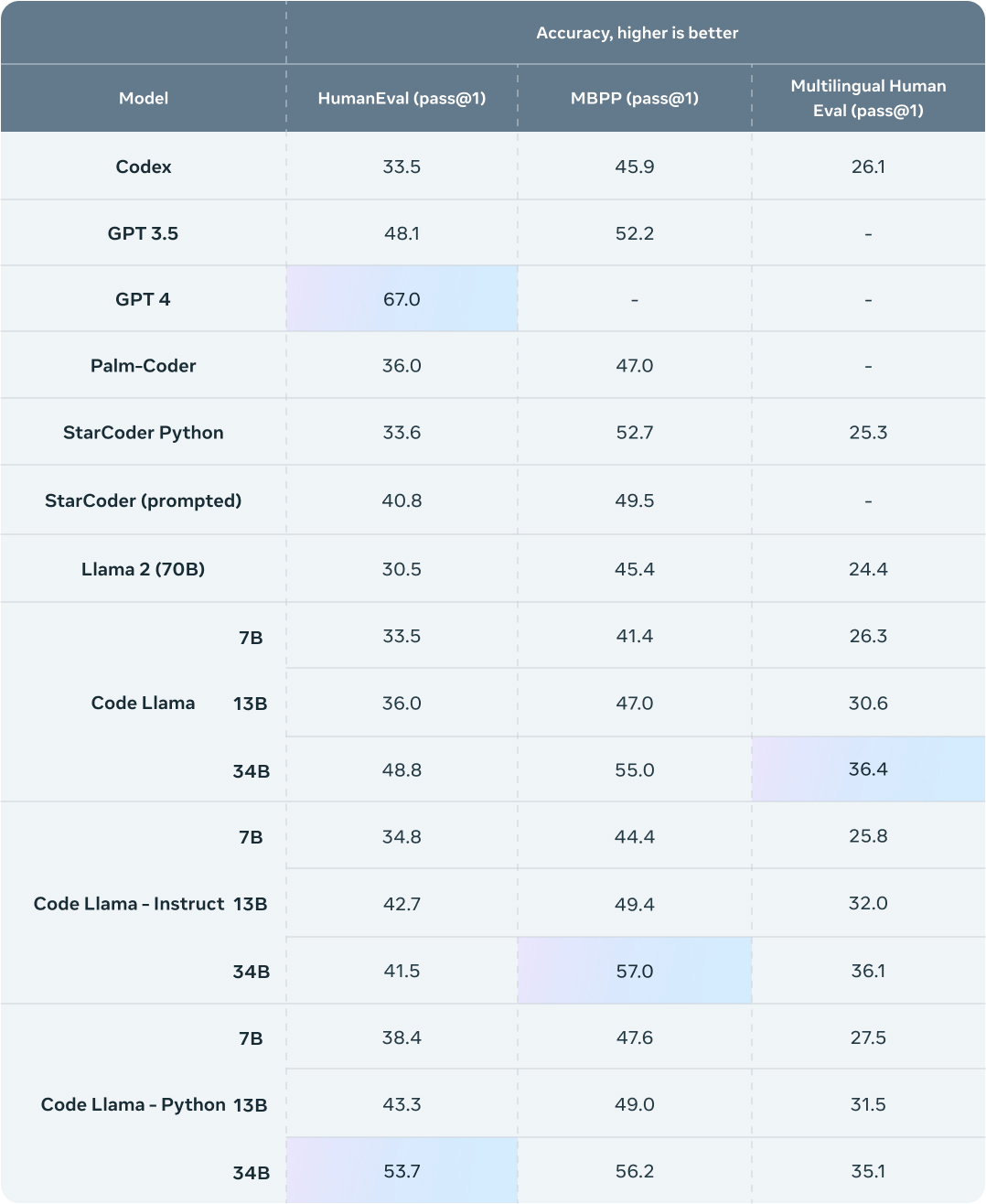
When evaluating Code Llama's performance in comparison to other state-of-the-art language models, it consistently outperformed open-source code-specific LLMs.
In particular, the 34 billion parameter Code Llama model achieved impressive scores on code-related benchmark datasets, comparable to the performance of ChatGPT.
This demonstration of superior performance highlights the potential of smaller, task-specific models to outperform larger, more general-purpose models like GPT 3.5.
Performance Highlights
- Benchmarks show it exceeds other public models on coding tasks: Initial benchmark testing by Meta shows Code Llama outperforming other publicly available models designed for coding. This includes models like Codex and AlphaCode.
- Approaches performance of proprietary models like GPT-3.5: While not quite reaching the same level, Code Llama gets close to proprietary models like GPT-3.5 in metrics like accuracy on test datasets. This is impressive given Code Llama's smaller size.
- Particularly strong on HumanEval and MBPP tests: Code Llama achieved state-of-the-art results for public models on the HumanEval and MBPP benchmarks. These tests assess skills like generating code from docstrings and descriptions.
The Impressive Potential of Unnatural Code Llama
While Code Llama's performance is already impressive, there is an even more advanced model mentioned in the paper: Unnatural Code Llama.
Although not discussed extensively in the announcement, Unnatural Code Llama exhibits exceptional performance, surpassing all other models by a significant margin.
The specific details of this model are not provided in the paper, but it is described as a fine-tuned version of the Python 34 billion parameter model. The performance boost achieved with just an additional 15,000 examples highlights the importance of carefully curated high-quality datasets in training machine learning models.
Advancements in Open-Source Models and Access to Code Llama
The release of Code Llama as an open-source model is a notable advancement in the availability of powerful language models for coding tasks.
By making Code Llama publicly accessible, developers and researchers have the opportunity to evaluate its capabilities, identify potential issues, and contribute to the improvement of this technology. Access to the Code Llama models can be obtained through a request form or directly through platforms like Hugging Face.
This shift towards open-source models, led by Meta, the company behind Code Llama, has the potential to drive innovation in the field of generative AI for coding. It may also pave the way for open-source alternatives to proprietary models like Codex.
The community-driven development of code-specific models can foster collaboration, enhance the quality of models, and accelerate advancements in coding workflows and software development.
Capabilities of Code LLaMa
Generate code from natural language prompts
Code Llama can produce code in languages like Python, Java, and C++ based on prompts written in natural language. For example, it could generate a Python function to calculate Fibonacci numbers when given a prompt like "Write a function to output the Fibonacci sequence up to n numbers."
Explain existing code
Code Llama can provide explanations of what existing code is doing by summarizing it in plain language. This could help developers understand complex code.
Fill in code (code completion)
Code Llama can suggest completions for partially written code, similar to autocomplete features in code editors. This allows it to assist with coding shorthand and speed up development.
Specialized Python and instruction-following versions
In addition to the base Code Llama model, there are versions specialized for Python and for following natural language instructions. The Python version provides enhanced abilities for that language, while the instruction model is better at interpreting prompts.
Potential Applications as a Developer Assistant
So with all the power of Code LLaMa, here are some of the use cases it can be used for:
Writing New Code
- Quickly generate code stubs from high-level prompts: Developers can use Code Llama to rapidly generate starter code from abstract prompts. This saves time compared to writing boilerplate code manually.
- Boost productivity by automating repetitive coding: For repetitive coding tasks like CRUD interfaces, Code Llama can greatly speed up development by generating standardized code automatically.
- Facilitate learning by providing code examples: Code Llama can assist developers who are learning by providing code examples for how to implement functionality described in plain language.
Documenting Code
- Generate comments and docstrings to explain code purpose: Code Llama can produce comments and docstrings that document what a section of code is doing in plain language. This helps improve code readability.
- Summarize complex code blocks in plain language: For long or complicated code blocks, Code Llama can analyze the code and generate a concise summary of the overall functionality in clear language. This aids other developers trying to understand the code.
Debugging Code
- Identify potential bugs from code snippets: By analyzing small sections of buggy code, Code Llama can often spot issues like infinite loops, off-by-one errors, etc. This helps developers pinpoint bugs.
- Suggest fixes based on full program context: Code Llama can take into account a whole program when diagnosing issues. This allows it to identify fixes that won't break functionality elsewhere.
- Explain unexpected behavior: For bugs that manifest in unclear ways, Code Llama can provide explanations of why the code is producing a given output. This makes the root cause of bugs easier to uncover.
Code Completion
- Complete partially written functions and classes: As developers type, Code Llama can suggest autocompletions for finishing functions, classes, and methods based on context.
- Recommend relevant variable names and parameters: Code Llama can propose meaningful variable names and parameter lists that fit with the surrounding code when completing functions.
- Expand coding shorthand into full code: Code Llama can expand shorthand like list comprehensions into full, explicit code. This saves developers time.
Concerns and Limitations of Code Llama
- Could enable inexperienced developers to produce buggy code: If used irresponsibly, Code Llama could allow developers without much experience to generate code they don't fully understand, resulting in bugs.
- Raises plagiarism issues in code generation: Generating code from prompts could make plagiarism easier by producing copies of existing code. Safeguards need to be in place.
- Requires monitoring to avoid generating harmful code: Without proper constraints, Code Llama could be prompted to output malicious code. It needs robust content filtering.
- Limited real-world testing so far: Most testing of Code Llama has involved synthetic benchmarks. More evaluation is needed on real-world tasks before widespread use.
Try Out Code Llama Yourself
If you'd like to experiment with Code Llama in a user-friendly environment, check out our friends at NimbleBox. Their chat platform provides free access to many of the latest open source large language models, including Code Llama.
Just go to https://chat.nbox.ai to start chatting with Code Llama and see what it can do - no setup required! The intuitive chat interface makes it easy for anyone to explore Code Llama's code generation and comprehension capabilities.
Make sure to select the model that includes "codellama-34b-8k" from the chatbox options. These model names may change but look for the ones with "codellama"
Wrapup
The release of Code Llama, a remarkable large language model focused on coding tasks, represents a major milestone in the field of generative AI for coding. Code Llama's ability to generate code, explain code segments, and assist with debugging showcases the immense potential of task-specific models in surpassing larger, more general-purpose models.
By outperforming existing code-specific language models, Code Llama highlights the narrowing gap between proprietary models and open-source models for specific applications.
The availability of Code Llama as an open-source model opens up vast possibilities for improving code development workflows, facilitating learning to code, and driving innovation in the field of programming.
Resources
 facebookresearch
facebookresearch






